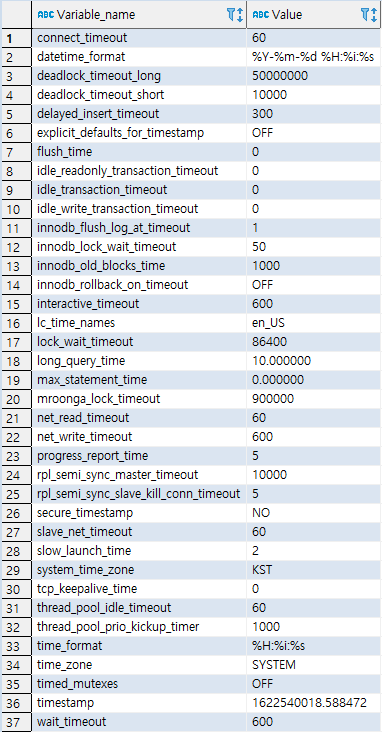
저장 프로시저 (Stored Procedure)
프로시저는 SQL Server에서 제공되는 프로그래밍 기능이며, 쿼리 문의 집합체라고 볼 수 있다.
간단하게로는 SELECT, INSERT, UPDATE, DELETE 등의 DQL, DML을 사용할 수 있으며,
조금 더 나아가서 IF 문이나 DECLARE, SET 등의 프로그래밍 문법을 사용할 수도 있다.
장점 및 단점
장점
- 보안성 향상
- 프로시저 단위로 실행 권한을 부여할 수 있기 때문에, 기본적인 보안 사고에 대처가 유연한 편이다.
- 네트워크 소요 시간 절감
- 쿼리를 다중으로 실행하는 경우, 한번의 호출을 통해 다중의 쿼리가 실행되기 때문에 네트워크에 대한 부담과 소요 시간을 줄일 수 있다.
- 운영 배포 용이성
- 별도의 WAS 서버 재기동 없이 SP 수정으로 조회, 수정, 추가 등의 가벼운 소스 변경 등이 가능하여, 긴급 배포 등이 용이하다.
단점
- 낮은 처리 성능
- 프로시저의 경우 성능이나 최적화가 부족하여 수행 능력이 떨어지며, 특히 문자열이나 숫자 연산에 사용하면 JAVA, C 등에 비해서 효율이 좋지 않다.
- 디버깅 및 유지보수의 어려움
- 배포, 버전 관리 등에 대한 이력 관리가 힘들다. (별도의 Description 사용)
- SP가 수정되는 경우 현재 운영 중인 서비스에 영향도 분석이 어렵다.
- APP에서 SP를 호출하여 사용하는 경우 문제가 생겨도 해당 이슈에 대한 추적이 힘들다. (별도의 에러 테이블 사용)
프로시저 생성, 수정, 삭제
기본적인 생성 방식은 다음과 같다.
USE [DB명]
GO
CREATE PROCEDURE [dbo].[프로시저명] (@파라미터명 NVARCHAR(10), @파라미터명2 int)
AS
BEGIN
-- 사용할 쿼리
SELECT 1 FROM test
END
GO
사용할 DB명과 프로시저명을 입력하여 사용하며, 파라미터의 경우 필요한 경우 자료형과 함께 입력하여 사용한다.
BEGIN과 END 사이에는 사용할 쿼리나, 프로그래밍 문법을 사용하여 실행할 수 있다.
수정의 경우, 생성과 기본 방식은 동일하며, CREATE가 아닌 ALTER를 사용하여 수정한다.
다만, 해당 SP의 경우 가장 기본적인 문법으로 현업에서는 아래와 같은 디스크립션을 추가하기도 한다.
USE [DB명]
GO
/*=============================================
작성자: 개발새발
생성날짜: 2021-09-13
업데이트날짜: 2021-09-13
설명: 프로시저 기본 생성 방식
exec 프로시저명 'TEST', 1
=============================================*/
ALTER PROCEDURE [dbo].[프로시저명] (@파라미터명 NVARCHAR(10), @파라미터명2 int)
AS
BEGIN
-- 사용할 쿼리
SELECT 1 FROM test
END
GO
삭제는 DROP 구문을 사용하여 삭제할 수 있다.
DROP PROCEDURE 프로시저명
프로시저 조회 및 실행
프로시저 조회는 sp_helptext를 사용하여, 텍스트 형식으로 결과를 표기할 수 있다.
sp_helptext 프로시저명
어떤 툴에서 DB를 연결하여 사용하느냐에 따라 다른데, 기본적으로 사용하는 SSMS (SQL Server Management Studio)에서는 GUI를 통해 저장 프로시저 스크립팅으로 CREATE, ALTER, DROP 등의 문법을 자동으로 생성해주며,
인텔리제이에서 데이터베이스를 연결하는 경우 SQL Generator (Ctrl + Alt + G) 통해 프로시저를 조회하는 것이 더 간단하다.
프로시저 실행은 exec 구문을 사용하여 해당 프로시저를 사용할 수 있다. 실행할 SP의 입력할 파라미터가 존재하는 경우, 순차적으로 해당 파라미터를 입력하면 정상적으로 실행된다.
exec 프로시저명 'TEST', 1'데이터베이스 > Mssql' 카테고리의 다른 글
| 저장 프로시저 활용 (IDENTITY) : 자동 증가값 생성, 조회 및 초기화 (0) | 2021.09.29 |
|---|---|
| 저장 프로시저 활용 (DECLARE, SET) : 변수 적용 (0) | 2021.09.25 |
| 저장 프로시저 활용 (IF EXISTS) : 데이터 유무 확인 조건문 (2) | 2021.09.14 |