NoSQL이란?
NoSQL은 SQL만을 사용하지 않는 데이터 베이스로 관계형 데이터 베이스와는 다른 방식으로 데이터를 저장한다. 다만, NoSQL의 경우 한 가지로 정의하기엔 힘든 부분이 RDBMS의 경우 쿼리 언어가 비슷한 반면, NoSQL의 경우 각 SQL에서 사용하는 쿼리 언어들이 다른 편이기 때문에 NoSQL로 엮여있는 데이터 베이스라고 하더라도 각각의 성격이 조금씩은 차이가 나는 경우들이 많다. 그렇기에 조금씩 성격은 다르지만, 대부분이 Schema-less 데이터베이스라는 점에선 동일하다.
MongoDB란?
큰 분류로는 Key-value, Document, Column-family, Graph 모델로 나뉘는데, 그 중 도큐먼트 지향 데이터베이스 시스템이 MongoDB이다. 그 외에도 Couchbase나 CouchDB 등이 도큐먼트 데이터베이스 시스템을 이용하고 있다.
Document Database의 경우, Key-Value Database와는 달리 값을 document 형태 (json, xml 등의 표준 형식) 로 저장한다는 점에서 차이가 존재한다.
[데이터 형식]
{
"_id" : "507f191e810c19729de860ea",
"name" : "테스트",
"phones" : ["010-1111-2222", "010-3333-4444"]
}MongoDB에서는 별도의 ObjectID를 입력하지 않은 이상은 위와같은 _id 형태로 자동으로 값이 부여가되서 저장이 되는데 ObjectID는 12byte 크기의 문자와 숫자로 구성된 값으로, 이 값은 각각의 의미를 가지고 있다.
4byte는 유닉스 타임스탬프, 5byte는 프로세스별로 생성되는 랜덤 값, 3byte는 자동으로 증가하는 카운터 로 구성되어 있다.
다만, ObjectID의 경우는 RDBMS의 서버와는 다르게, 분산 환경 지원을 위해 서버가 아닌 클라이언트에서 해당 키를 생성하는 차이점이 존재한다. (클라이언트에서 키를 생성하기 때문에 중복된 값을 생성할 가능성 자체는 존재하나 해당 부분은 낮추기 위해 ObjectID의 패턴이 존재, 또한 상당히 낮은 편)
[ObjectId 구조]
ObjectId('507f191e / 810c19729d / e860ea')
-- 507f191e : UNIX Timestamp
-- 810c19729d : Random Value
-- e860ea : Count
주요 특징 (기술 요소)
RDBMS의 ACID와는 다른 BASE를 채용하였는데, ACID를 채용한 RDBMS는 데이터의 일관성을 BASE를 채용한 NoSQL의 경우 데이터의 가용성을 중시하여, 시스템이 서비스를 정상적으로 제공할 수 있는 상태를 우선시한다. 해당 내용은 CAP (Consistency - 일관성, Availbity - 가용성, Partition tolerance - 분할 내성)을 기반으로 하고 있으며, 세부 내용은 아래와 같다.
- Basically Available (가용성) : 언제든지 사용할 수 있다 (무중단 서비스 가능)
- Soft State (소프트 상태) : 외부의 개입이 없어도 정보 변경 가능 (각각의 데이터가 도달한 시점에 데이터가 갱신)
- Eventually Consistent (결과적 일관성) : 일시적으로 일관적이지 않아도 최종적으론 일관적인 상태가 되어야함 (복제 메커니즘에 의해 모든 서버에 데이터 복제가 동시에 실행될 순 없으나, 최종적으로는 모든 서버에 데이터가 복제)
주요 특징 (데이터 형식)
MongoDB의 경우 데이터를 관리하기 위한 형식으로 JSON (JavaScript Object Notation)과 BSON (Binary JSON) 형식을 사용하고 있다.
두 형식을 사용하는 이유는 JSON의 경우 텍스트 기반으로 구문 분석이 느리고, 공간 효율성이 상대적으로 나쁜편이기 때문에 JSON 구조를 가져가면서 기계가 읽기 쉬운 형태인 binary 형태로 변경하여 저장하는 형식으로 해당 문제를 해결하였다.
JSON의 경우는 Javascript에서 객체 생성 시 사용하는 표현식으로 {"hello": "world"} 형식과 같이 Key : value 형태의 데이터를 가지고 있고, BSON의 경우 JSON을 이진 형식으로 인코딩한 형식으로 \x16\x00\x00\x00\x02hello\x00\x06\x00\x00\x00world\x00\x00 와 같은 구조를 지닌다.
데이터 입출력시에는 JSON을 사용하며, 데이터 저장 시에는 BSON을 사용한다. 이와 같은 구조는 실제로는 데이터베이스 내부에서 처리가 이루어지기 때문에 표면적으로는 구조를 확인하는 일은 드문편이다.
주요 특징 (용어)
MongoDB의 경우 Document 기반 데이터 베이스로, RDBMS와 명칭적인 차이는 존재하나 비슷한 역할을 가진다.
| MongoDB | RDBMS |
| 데이터베이스 (Database) | 데이터베이스 (Database) |
| 컬렉션 (Collection) | 테이블 (Table) |
| 도큐먼트 (Document) | 로우 (Row) |
| 필드 (Field) | 칼럼 (Column) |
주 사용처
MongoDB와 같은 NoSQL의 경우, 대용량 데이터에서도 원하는 데이터를 빠르게 찾을 수 있고 스키마가 존재하지 않기 때문에 정형 혹은 비정형의 대용량 로그성 데이터와 제일 궁합이 잘 맞는 편이다. 필요에 따라서, 샤드 클러스터를 구성하여 데이터 분산과 Scale-out 등을 통해 지속적인 유지보수 또한 쉬운 편이다.
다만, 이러한 로그성 데이터뿐만 아니라 여러 서비스에서 조금씩 다르게 사용하는 공용 데이터나 조금씩 다른 형태로 들어오는 데이터 등 스키마가 존재하지 않는 자유로움으로 인해 여러면에서 활용성은 점점 늘어나는 추세이다. 해당 부분은 각 데이터베이스 특성을 활용하여 설계하면 효율적인 활용이 가능하다.
마치며
이전에는 몽고 DB 쓰지 마세요 라는 기사와 검색이 있을 정도로 여러가지 이슈가 존재하였으나, 현재는 전통적인 RDBMS를 제외하면 가장 많이 사용되는 데이터베이스기도하고 데이터가 점점 다량화되어가는 추세에 있어서는 RDBMS와 NoSQL을 혼용하여 사용하는 것이 좋은 선택지임은 분명하다.
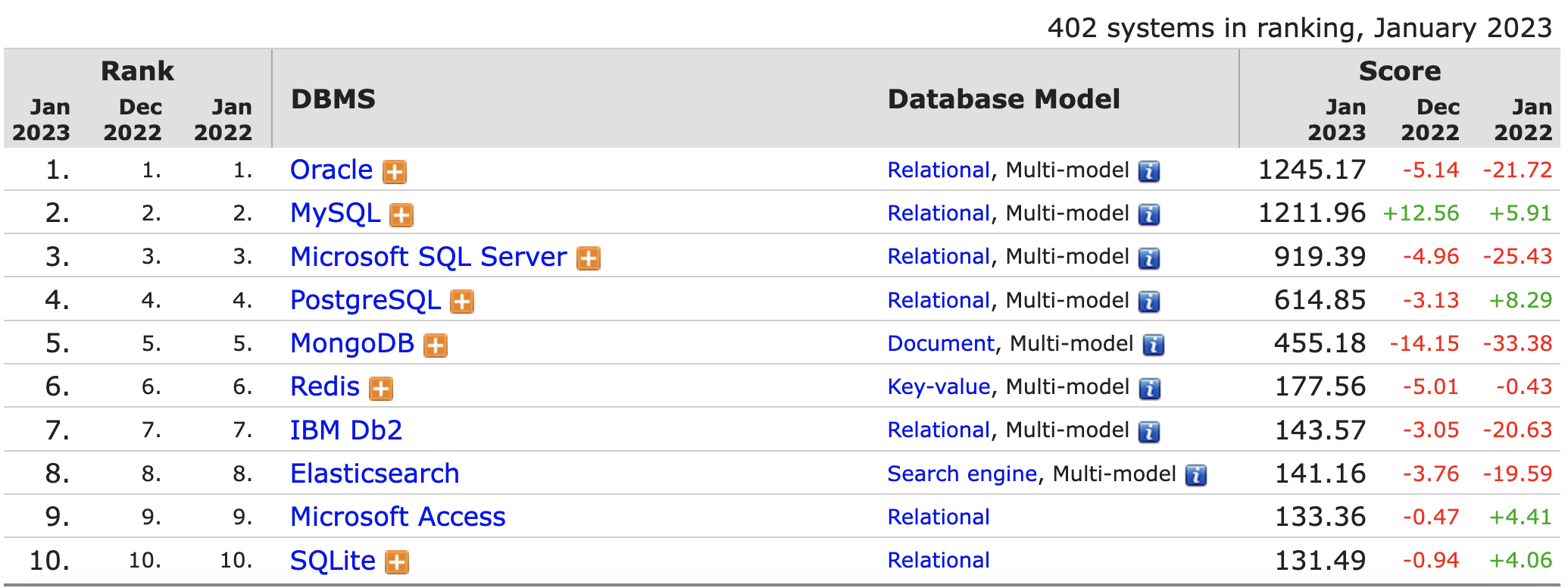
출처 : https://db-engines.com/en/ranking
DB-Engines Ranking
Popularity ranking of database management systems.
db-engines.com